
中国平均工资都7000了,为什么我还这么穷?
2019年04月04日 16:07:10
来源:凤凰网知之
作者:凤凰WEEKLY

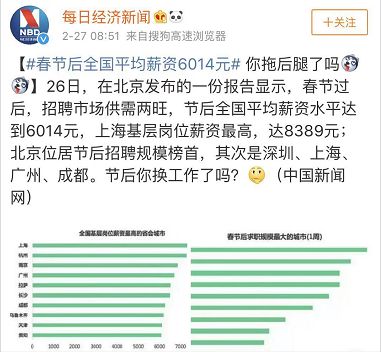
一条关于“平均工资”的报告,被顶上了热搜。报告显示:春节后招聘市场很火,平均薪资高达6014元。上海连基层岗位薪资,都高达8389元。评论区一片哀嚎,“我又拖祖国后

一条关于“平均工资”的报告,被顶上了热搜。
报告显示:春节后招聘市场很火,平均薪资高达6014元。上海连基层岗位薪资,都高达8389元。
评论区一片哀嚎,“我又拖祖国后腿了”的喊声不绝于耳。
近年来,这类“权威调查”层出不穷:
《2018年全国平均工资7850元,你拖后腿了吗?》
《90后没有性生活了:30%的人无性且单身5年以上》
《互联网巨头:公司员工平均年薪50万!》
《就业寒冬来了!全国平均32人竞争一个岗位》
《中国男女比7连降,3000万男性将“打光棍”!》
《长期单身会短命:单身男性比已婚死亡风险增加20%》
看到这些报告,很多人大呼:我不信!但是除了翻个白眼之外,好像也说不出哪里有问题。毕竟“数据不会说谎”。
数据真的那么可靠吗?
并非如此。恰恰相反的是,有大把方法,能让统计数字说谎。
你看到的数据
很可能是“高级订制”
年初,某招聘平台发布报告,报告中显示,2018年年末,全国半数白领拿到年终奖,并且平均奖金高达7100元。
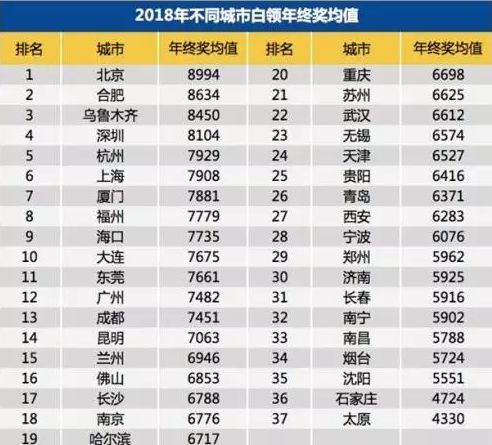
真有这么多人拿到了年终奖??难道1毛钱都没拿到的,只有我一个???
点开评论区,原来大家都一样。
当数据和感受严重不符时,很多人会认为是自己错了。或许自己就是混的比较差的那批人...
可是错的不一定是你,也可能是数据本身。
这类数据,通常都以问卷抽样调查形式进行。偏偏抽样调查,是一种很容易被干扰的调查方式。
首先是样本规模。
我们可以在广州市,调查冬天穿羽绒服的人群比例。但不能声称:调查显示,全国人民冬天几乎都不穿羽绒服。
我们看到的很多调查报告,实际上就是类似这样操作的。一个网站可能只发了几百份问卷,就敢发布“全国XX调查”。
其次是抽样方法。
不是样本规模够大,数据就一定准确。
有一个经典段子:
电话调查显示,美国100%的家庭拥有电话。
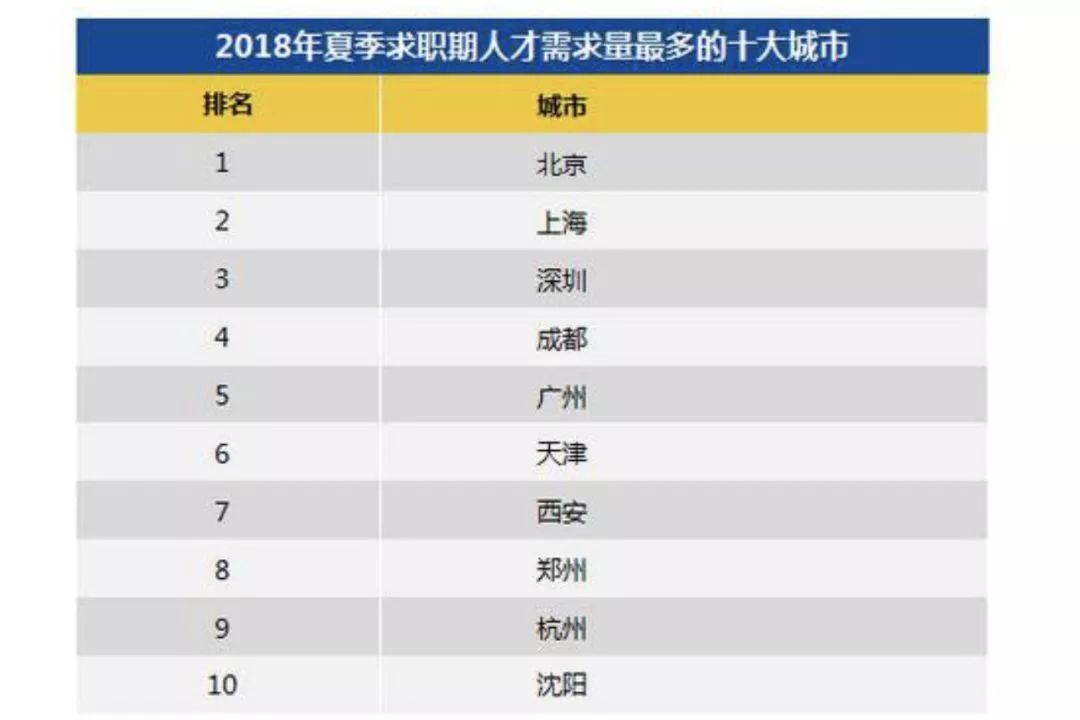
同样的例子有很多。譬如某招聘平台,通过对平台的数据库分析,得出了“2018年夏季,求职人才需求量最多的10大城市”。
这份报告其实该叫 ”2018年夏季,在该招聘平台发布职位最多的城市”。
要保证调查数据的准确,需要花费不少精力。
但如果想要“私人订制”一个对自己有利的数据,就轻松很多了。
例如某线上理财平台,做了一个调查。他们得出结论:超过半数的受访者,倾向于使用互联网理财平台。
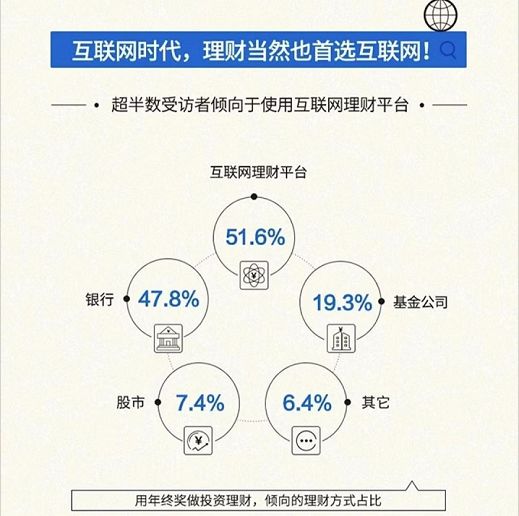
但这份报告中,对于样本的介绍只有一句话:对全国多个城市年终奖数据进行调查。
用这种调查方式,甚至可以调查出:全国超半数受访者,都使用本平台理财呢。
同样的骚操作,很多招聘网站也干过。某招聘平台有过一个报告:近八成的白领,都在寻找新的工作机会。
但有一个问题,那些不想找工作的人,上招聘网站干啥?闲着没事?(真的有4.4%的用户这么闲)
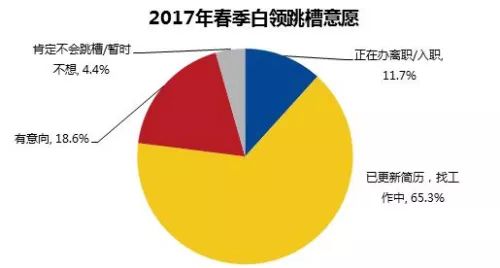
这类调查无异于在饭店外面问排队的顾客:会不会选择在该店就餐?属于废话。
数据解读方式
是如何指鹿为马的?
即使样本够大,抽样方法也足够科学,调查呈现的结果,仍然可以被主观意志所左右。
修改数值、编造数据是最低劣的手段,更高明的是,根据需求采用不同的分析策略。
最典型的例子就是人尽皆知的“被平均”。
有网友云“拿我的工资和马云平均,我也能进福布斯”。

我们可以把这个案例放大到现实世界。据统计,全球最富有的26个人的财富总和,相当于最贫穷38亿人的财富总和。这38亿人构成全球一半人口。
假设最富有的26人财富共2600000000元,每人平均100000000元资产,那最贫穷的38亿人平均只有0.68元的资产。
如果“被平均”一下呢?
38亿最贫穷的人,人均资产变为了1.36元,直接翻了一倍。
资源是不会平均分配的。比起均值,众数和中位数也许更能说明问题。
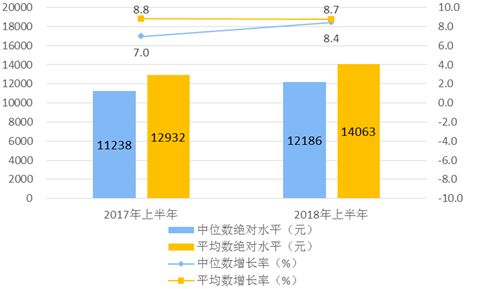
2018年上半年居民人均可支配收入平均数与中位数 图片、数据来源:国家统计局
众数是指在统计中,具有明显集中趋势点的样本,代表统计样本的一般水平;中位数是按顺序排列的一组样本数据中,居于中间位置的样本。
以马云和网友的故事为例:
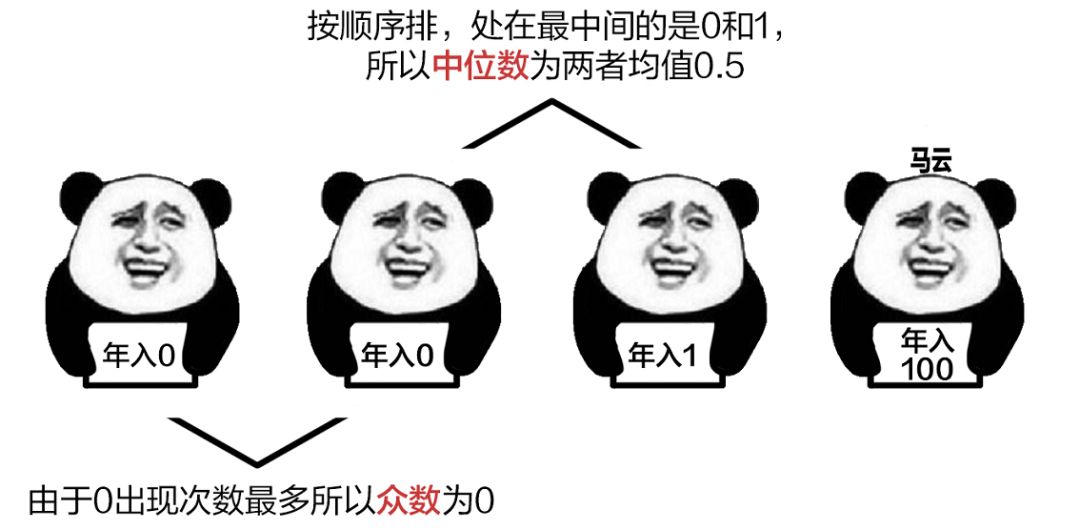
假设两名网友收入为0元,一名网友的收入为1元,马云的收入为100元,那么统计数据的整体众数为0元。
将4个人的收入按顺序排列,排在最中间的两个数之和为1,取个平均数,可以得出四人年收入的中位数是0.5。
收入的众数,可以体现多数人的收入水平。收入的中位数,可以让大家知道,自己的收入,处在什么位置。
一份统计报告中,只要列出众数和中位数,就能得到相对中肯的结果。但就是有人故意回避这些数据,专拿平均数说事,非蠢既坏。
除了有目的地选用数据,还可以别有用心地解读数据。
下图中的两个对比项曲线无比吻合,如果不知道图表的具体内容,一定会认为两项数据,有紧密的相关性。
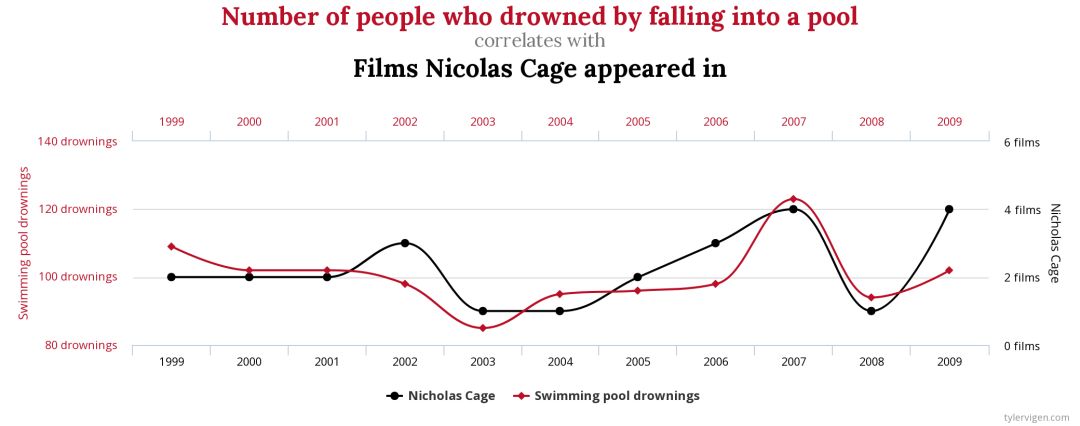
其实这两条曲线,分别代表 [尼古拉斯凯奇每年在电影中的出镜次数] 及 [每年游泳池里溺死的人数] 。
显然这是八竿子打不着的两件事,曲线的吻合实属巧合。
谁让这是个充满巧合的世界呢?
在1989年的一次调查里,调查者发现法国人爱吃的食物高脂肪、高蛋白、高热量,但法国的肥胖人口却只有10%,冠心病发病率和死亡率,还比其它西方国家低得多。
鉴于法国盛产红酒,法国人也向来有喝红酒的习惯,研究人员便“顺理成章”地推测:“每天适当饮用红酒有利于心血管健康,可预防心血管疾病的发生”。

实际上,并没有医学证据支持红酒有利于心血管健康的结论。[法国人心血管疾病发病率低] 与 [法国人爱喝红酒] 只是两个独立事件。
这样的谣言广为传播,要拜红酒商人所赐。
巧合无处不在,但是把巧合放在一起,并暗示相关性或因果关系,就其心可诛了。
不仅能用数字骗人
图表形状也能用来误导
在数据领域,谎言绝不仅仅限于数字和样本,它同样是视觉的艺术。
为了直观解读,数据通常会做成图表。在设计图表过程中,有许多误导性的手法。
修改坐标轴
修改坐标轴中,截断Y轴的操作最为常见。
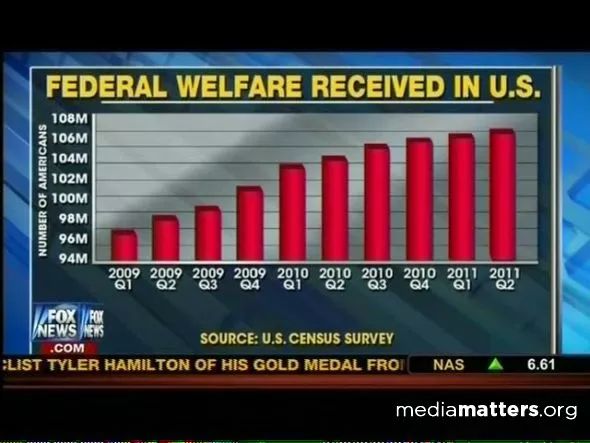
上图是08年金融危机后,美国领取政府福利的人数增长情况。
乍一看,每个季度都有巨量增长。柱状图赫然呈现出:联邦政府与日俱增的财政压力。
美国人民看到后,内心对政府充满了感激。
但如果仔细观察,会发现这张图的Y轴不是从0开始,而是从94M开始的。如果将Y轴展开,改为从0开始,这张图就会呈现以下效果:
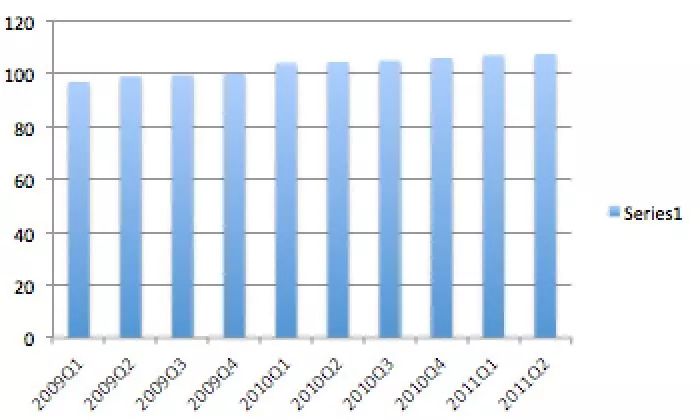
是不是马上变得平平无奇了?
美国民众的感激之情,瞬间能消散80%。
还可以换一个更直观的例子。

上图是2017年维密大秀的现场采访。
图中左侧是主持人,右侧是身高为178cm的超模何穗、奚梦瑶。
图中看到,主持人和两位超模几乎平起平坐,观众可以大胆推测:主持人的身材一定也相当优越。
事实并非如此,因为这张图截去了Y轴。我们将Y轴打开,这张图长这个样子:

此外,还可以拉伸、挤压坐标轴。同一份数据,做出的图坐标刻度不同,可以呈现出完全不同的效果。
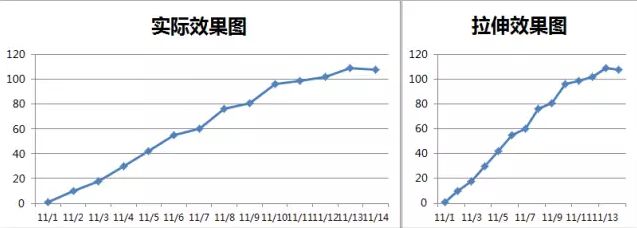
选用不同的图表
除了利用坐标轴误导读者之外,作图者还经常利用图表特性掩盖、扭曲关键信息。
比如用累积数据图代替阶段数据图。
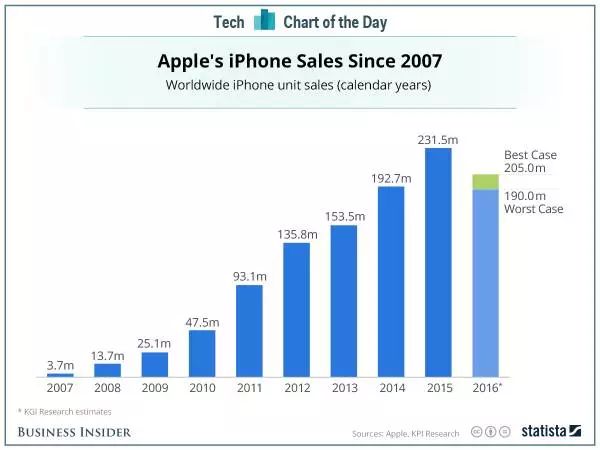
上图是苹果手机的历年销量,图中可以看到2016年销量数据预测,将出现较大下滑。
如果作图人想掩盖这一信息,可以将历年销量图改为累计销量图,这部分信息就会在图中消失无踪。
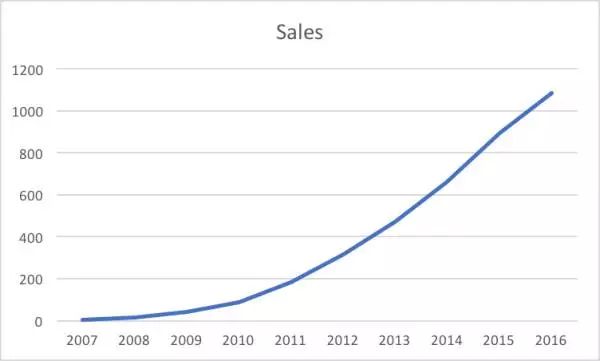
利用图表特性扭曲关键信息
比如利用3D图表的特殊透视误导读者。
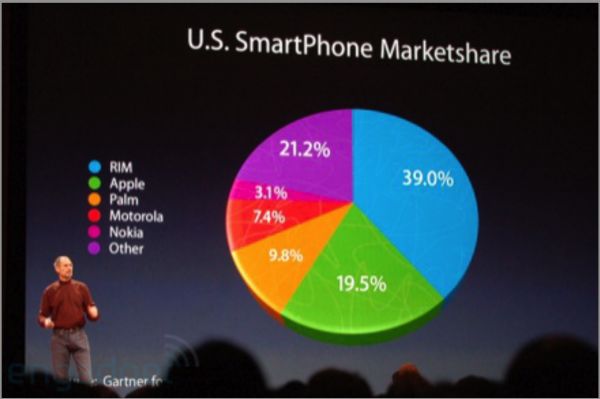
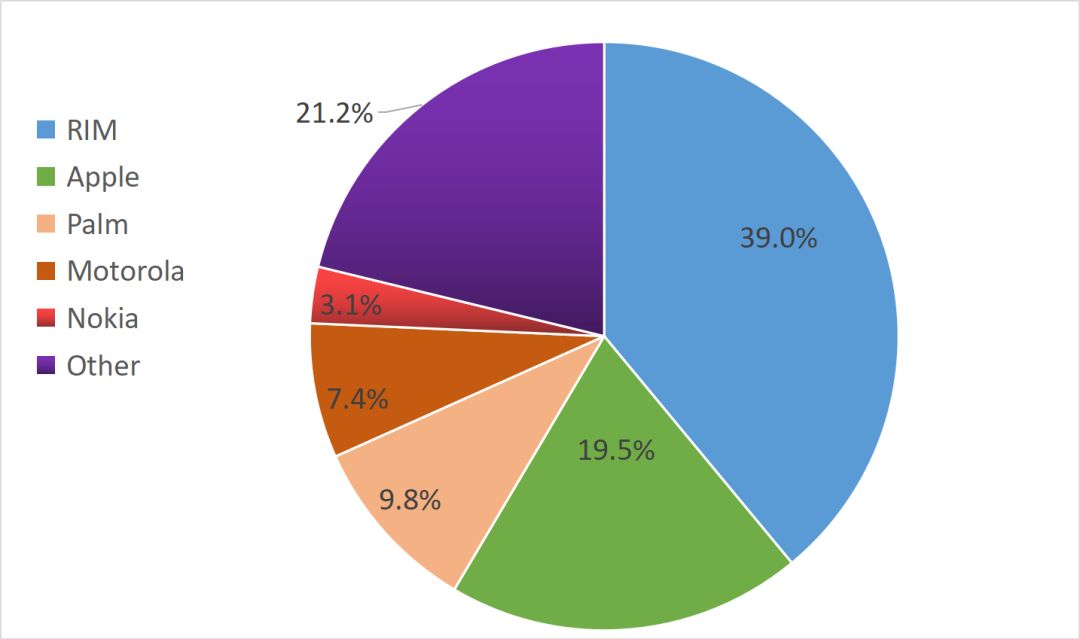
下图是2008年乔布斯在发布会上引用的数据,显示当时苹果占据了智能手机市场19.5%的份额。
在这张3D图中,由于阴影的存在,iPhone所占据的绿色区域会看起来会比实际上更大。
将这张3D饼状图还原为平面图,如下,视觉效果明显差了很多。
作为世界级的演讲大师,这种失真的细节是不会逃过乔布斯的眼睛的。
换句话说,他故意的。
看了上述这些,通过人为手段操纵数据,得到某个结论的伎俩后,再来看看那些“耸人听闻”的标题:
《2018年全国平均工资7850元,你拖后腿了吗?》
《90后没有性生活了:30%的人无性且单身5年以上》
《互联网巨头:公司员工平均年薪50万!》
《就业寒冬来了!全国平均32人竞争一个岗位》
《中国男女比7连降,3000万男性将“打光棍”!》
《长期单身会短命:单身男性比已婚死亡风险增加20%》
是不是焦虑的感觉少了许多?
此外,即使统计者没有数据曲解,而是竭力想从数据中得出准确信息,也未必能如愿。
因为现实世界的变量实在太多。
譬如说预测天气吧。我们早就会呼风唤雨(人工降雨),还能控制蓝天,天上还飘着数以百计的卫星,结果呢?
天气预报还没有萧敬腾准。

经济学家是如何看待平均数字的?为什么从经济学角度来说,不可能做到人人均富?经济学家自己如何看待做事所需要的“成本”问题?
知之×中信书院推出兰德尔·巴特利特教授的经济学课程
《斯坦福大学经济学思维课》
扫描下方二维码,发现“知之”微信频道,每周半小时,像经济学家一样思考,遇见更理性的自己。关注我们,更多经济科普内容为你呈现!





[责任编辑:高晓晨 PSY087]
责任编辑:高晓晨 PSY087
- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128


